MFEM Community Workshop
September 22-25, 2026
Georgia Tech + Virtual

Overview
The MFEM team, together with Georgia Tech's School of Computational Science and Engineering and the Open Source Program Office, invite you to the 2026 MFEM Community Workshop, which will take place on September 22-25, 2026 in a hybrid format: in-person at Georgia Tech + virtually on Zoom. The goal of the workshop is to foster collaboration among all MFEM users and developers, share the latest MFEM features with the broader community, deepen application engagements, and solicit feedback to guide future development directions for the project.
We encourage you to join us in person if you can! As you make travel plans, please note that the first day of the workshop (September 22) will be reserved for a hands-on MFEM tutorial.
Please contact the meeting organizers with any questions: mfem@llnl.gov
Registration
If you plan to attend, either in-person or virtually, please register no later than September 11th.
-
In person: The registration fee for in-person attendance is $150 for regular participants and $75 for students. After completing this registration form, you will receive separate payment instructions for the registration fee in a follow-up message.
-
Remote: There is no registration fee for remote participants. Zoom details will be distributed prior to the event date.
Venue
The workshop will take place at Georgia Tech (GT) in Atlanta, Georgia. GT is about a 30-minute drive from Hartsfield-Jackson Atlanta International Airport. Information about the meeting room and a map will be available soon.
Meeting Format
This will be the third hybrid edition of the MFEM community workshop and the sixth overall. Highlights of the program include:
- Free guided tutorial (to be held on the first day of the workshop, September 22)
- Tutorial registration is separate as part of the LLNL High Performance Computing Innovation Center’s summer tutorial series
- Hybrid format: Georgia Tech or on Webex
- Great for new users!
- Project news and roadmap
- Application developer talks – submit your abstract with registration
- Student lightning talks – submit your abstract with registration
- In-person poster session
- Visualization contest
- Office hours
See also the agendas for the previous 2025, 2024, 2023, 2022, and 2021 MFEM workshops.
Workshop participants are encouraged to join the MFEM Community Slack workspace to communicate with other MFEM users and developers before, during and after the MFEM workshop.
Agenda
Details will be posted soon.
Simulation and Visualization Contest
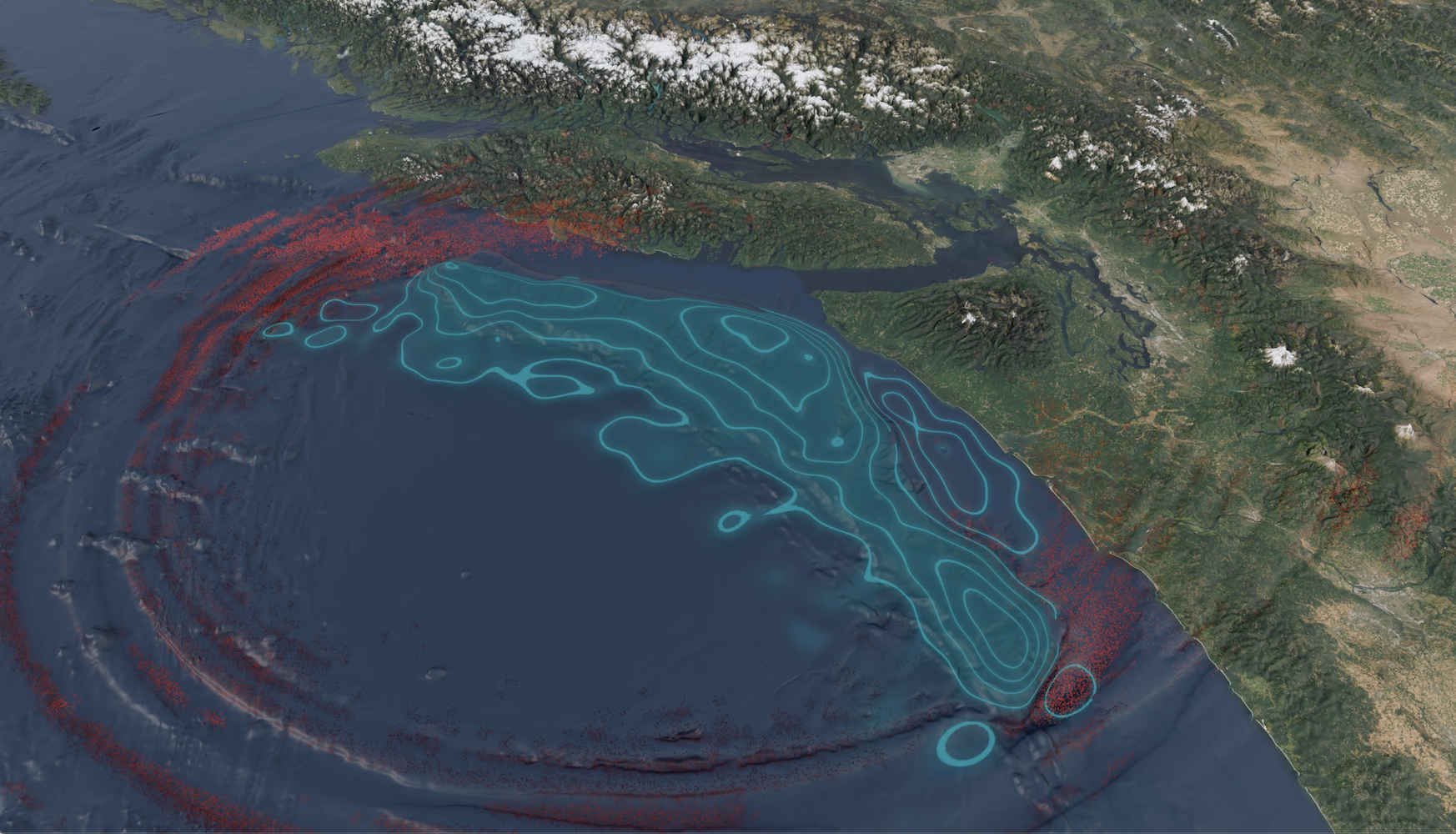
We will be holding a simulation and visualization contest open to all attendees. Participants can submit visualizations (images or videos) from MFEM-related simulations. The winner of the competition (selected by the organizing committee) will receive an MFEM T-shirt. We will also feature the images in the gallery. Here are the winners from the 2025 workshop:
Virtual Backgrounds
We invite workshop participants to use the virtual backgrounds designed for this event. Click each image to enlarge, then right-click to save locally.






Workshop Sponsors
We are seeking sponsors to help support this year's workshop. Sponsorship helps offset the costs of hosting an in-person event, lower registration fees for attendees, and support student travel and attendance.
Event sponsors will be recognized on the workshop website, mentioned during the sessions, and will have the opportunity for a poster display or table. While we welcome donations of any size, we offer the following suggested tiers of sponsorship:
- Bronze Sponsor – $2,000
- Listed on website, recognized during opening and closing talks
- Silver Sponsor – $4,000
- Listed on website, recognized during opening and closing talks
- Two technical sessions listed as sponsored by the organization
- Gold Sponsor – $6,000
- Listed on website, recognized during opening and closing talks
- Two technical sessions listed as sponsored by the organization
- Poster/Table in the workshop room for the duration of the meeting
If your organization is interested in sponsoring the workshop, please contact the organizers at mfem@llnl.gov.
About Livermore and LLNL
Founded in 1869, Livermore is California's oldest wine region, framed by award-winning wineries, farmlands, and ranches that mirror the valley's western heritage. As home to renowned science and technology centers, Lawrence Livermore and Sandia national labs, Livermore is a technological hub and an academically engaged community. It has become an integral part of the Bay Area, successfully competing in the global market powered by its wealth of research, technology, and innovation.
For more than 70 years, LLNL has applied science and technology to make the world a safer place. World-class facilities include the National Ignition Facility, the Advanced Manufacturing Laboratory, and the Livermore Computing Center hosting the world's fastest exascale supercomputer, El Capitan.
About Georgia Tech
The Georgia Institute of Technology (Georgia Tech or GT), is one of the nation's top public research universities with more than 50,000 students who study in person at the main campus in Atlanta, at off-campus instructional sites such as Georgia Tech-Europe in France, and through distance and online learning.
GT's School of Computational Science and Engineering creates future leaders who keep pace with and solve the most challenging problems in science, engineering, health, and social domains. This research focuses on high-performance computing, modeling and simulation, and large-scale Big Data analytics powered by machine learning and artificial intelligence to enable breakthroughs in scientific discovery and engineering practice. GT's Open Source Program Office (OSPO) supports the development, maintenance, and sustainability of open-source research software.
Organizing Committee
Holly Auten ┊ John Camier ┊ Brendan Keith ┊ Tzanio Kolev ┊ Justin Laughlin ┊ Will Pazner ┊ Socratis Petrides ┊ Sohail Reddy ┊ Syun'ichi Shiraiwa ┊ Qi Tang